PyTorch基础
0.前提
什么是 PyTorch
PyTorch 是一个 Python 优先的深度学习框架,动态计算图让它比静态图更灵活、更容易调试
⚠️说明:PyTorch更推荐在Linux上学习和使用,并且如果想要结合显卡操作,强烈不推荐在虚拟机上使用。有能力的同学可以给自己的电脑安装双系统。本笔记只记录在Windows上的操作
在此之前需要学会的知识或者环境
-
Python编程基础:PyTorch 主要是用 Python 编写的, 虽然目前也支持C++和JAVA语言,但是现在市面上能以这两个语言编写Torch的教程还很少。
-
数学基础:了解线性代数、微积分等基础数学知识。本教程不需要精通,如果已经忘记,强烈推荐观看 3Blue1Brown 的课程。
-
机器学习基础:了解机器学习的基本概念。这些知识点即使不了解,我也会在本笔记中简单介绍。如果想学习比较扎实的基础,推荐周志华的《机器学习》这本书(大家亲切的称他为西瓜书,因为整本书都在教你用机器学习算法如何挑到好吃的西瓜,,,)。
安装pytorch
❗前提:你需要安装python,建议python3
访问 PyTorch 的官方网站,网站提供了一个方便的工具,可以根据你的系统配置(操作系统、包管理器、Python版本以及CUDA版本)推荐安装命令。
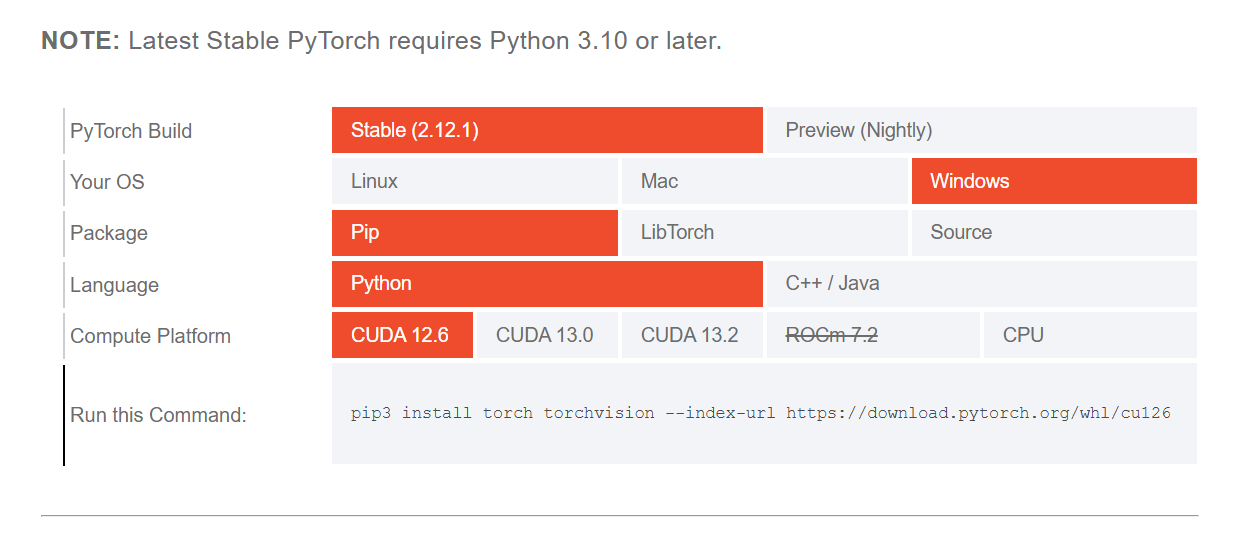
❗在这里你能看到CUDA的版本选择,如果你的显卡支持CUDA,那么请选择CUDA版本,否则请选择CPU版本。
# 安装pytorch,torchvision和torchaudio
pip3 install torch torchvision torchaudio
安装cuda
CUDA是英伟达是NVIDIA推出的通用并行计算平台和编程模型,支持多种编程语言。
CUDA Toolkit是NVIDIA提供的一个用于GPU开发的工具包。它可以帮助开发人员使用GPU进行深度学习、机器学习、图像处理等等任务。
CUDA版本与PyTorch版本是有严格的对应关系的,同时根据我本人安装经历,CUDA版本和英伟达显卡驱动版本也是有严格对应关系。
访问 NVIDIA CUDA Toolkit 下载界面,同PyTorch一样,NVIDIA也提供了工具,根据你的系统配置推荐下载的安装包。
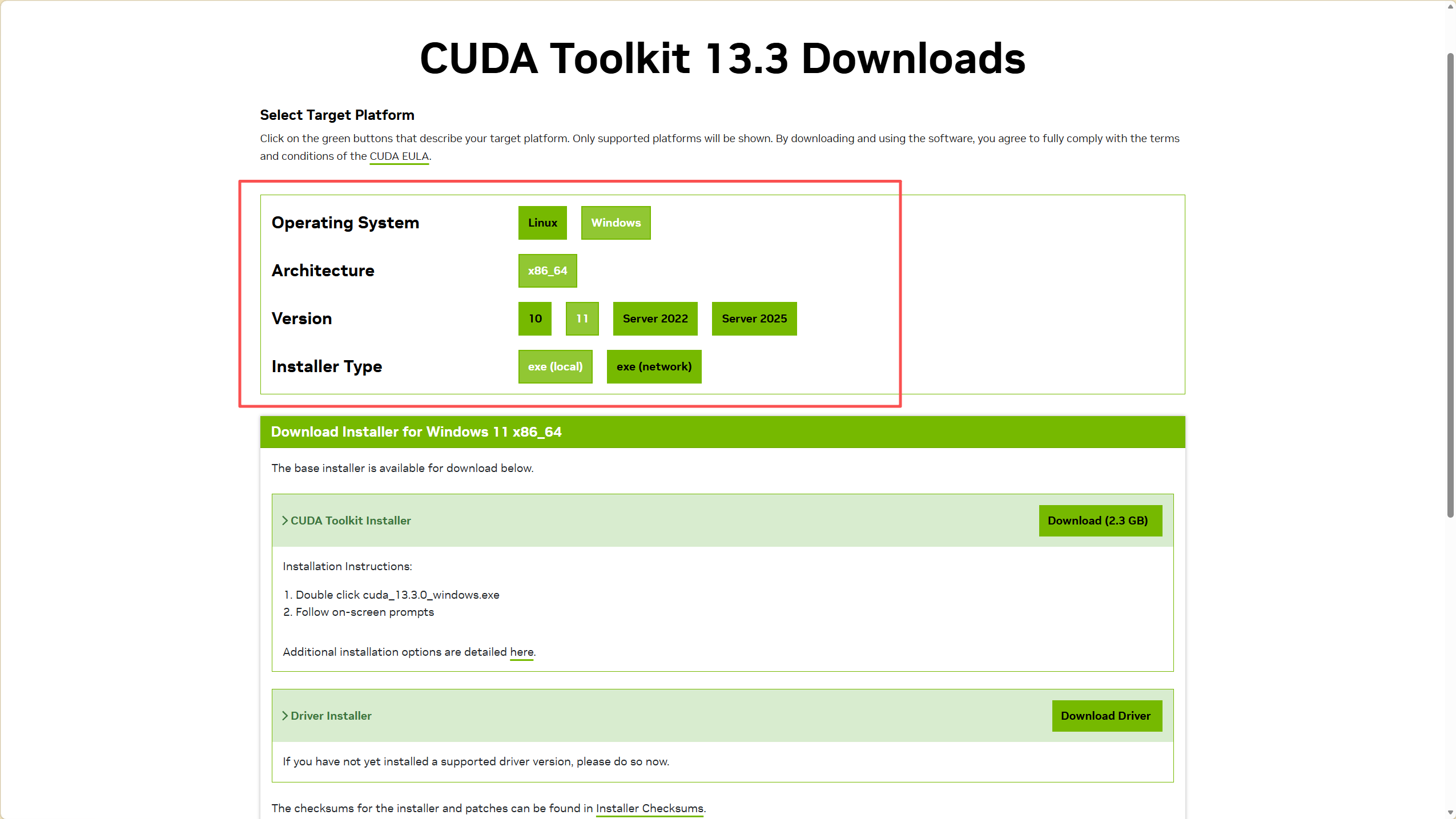
下载好之后点击安装包,开始安装。
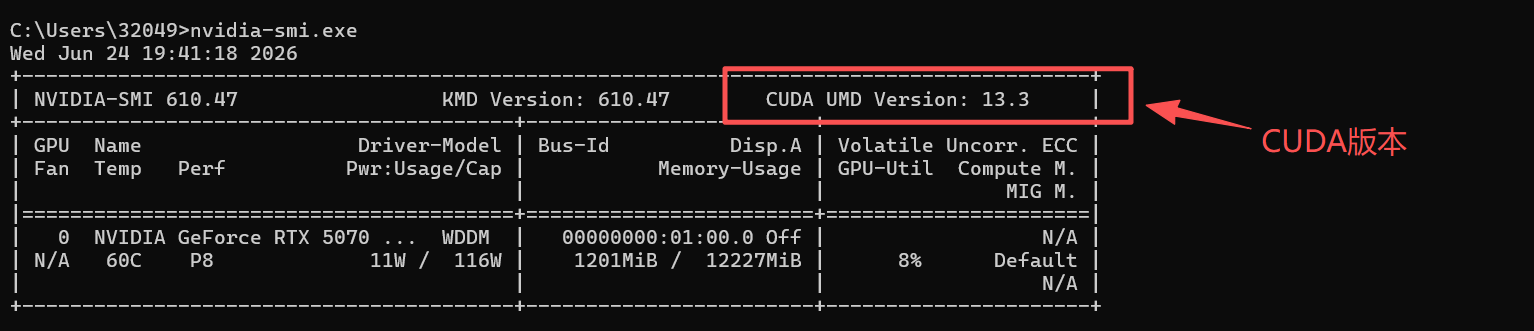
✔️安装好后,在命令行中运行以下命令,即可查看英伟达的版本。
nvidia-smi.exe
其他
除此之外,还推荐使用PyCharm作为Python的开发IDE
验证基础环境
我们创建一个简单的Python文件,用来检查PyTorch的运行以及对GPU的支持
这个代码你暂时不需要了解他在做什么,不需要做任何修改,可以直接运行
## 在这里引用PyTorch
import torch
## 如果支持CUDA,则使用GPU,否则使用CPU
DEV = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"设备: {DEV}")
print("\n" + "=" * 55)
print("GPU 支持")
print("=" * 55)
if DEV.type == "cuda":
print(f"GPU: {torch.cuda.get_device_name(0)}")
wx = torch.randn(100, 200, device="cuda")
wy = torch.randn(200, 100, device="cuda")
# 矩阵乘法
_ = wx @ wy; torch.cuda.synchronize()
else:
print("未检测到 GPU, CPU 模式运行")
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
y = torch.tensor([[5.0, 6.0], [7.0, 8.0]])
print(f"x:\n{x}\ny:\n{y}")
print(f"x + y:\n{x + y}")
如果你是NVIDIA显卡用户,并且正确安装了CUDA,那么运行结果如下:
设备: cuda
GPU: NVIDIA GeForce RTX 5070 Ti Laptop GPU
tensor([[ 5.2766, 11.5421, -5.2882, ..., -15.2835, -12.4100, -9.0720],
[ 18.3162, -23.5693, 24.4115, ..., -6.1360, 24.1747, 3.2343],
[ 0.4944, 21.7948, 2.2534, ..., -16.5061, 22.3207, -8.2079],
...,
[ 13.0756, 8.9047, -10.7848, ..., -11.7192, -1.8161, -17.7984],
[-10.8788, -1.6606, 2.6119, ..., 22.6208, -27.0059, 8.9193],
[ 1.0328, -4.5920, -6.0699, ..., -14.9712, -2.0496, 3.2142]],
device='cuda:0')
如果只使用了CPU计算,那么运行结果如下:
设备: cpu
未检测到 GPU, CPU 模式运行
x:
tensor([[1., 2.],
[3., 4.]])
y:
tensor([[5., 6.],
[7., 8.]])
x + y:
tensor([[ 6., 8.],
[10., 12.]])
如果正确打印出了以上结果,那么恭喜大家可以继续学习PyTorch了。
1.Pytorch到底可以做什么
或者说深度学习到底可以做什么。简单来说,深度学习可以让电脑像人一样,通过大量例子自己学会做某件事,而不是程序员一条条写死规则。
而PyTorch就是一个深度学习框架,可以快速实现深度学习模型。让你不用从零开始造轮子,直接用现成的零件快速搭出能学习的模型。
传统编程像是给电脑写一本极其详细的操作手册,每一步都规定死。而深度学习更像是给电脑看海量例子,让它自己领悟规律。这个对比的关键在于“规则”和“数据”的角色互换。
我们举个简单的例子:外卖员送餐
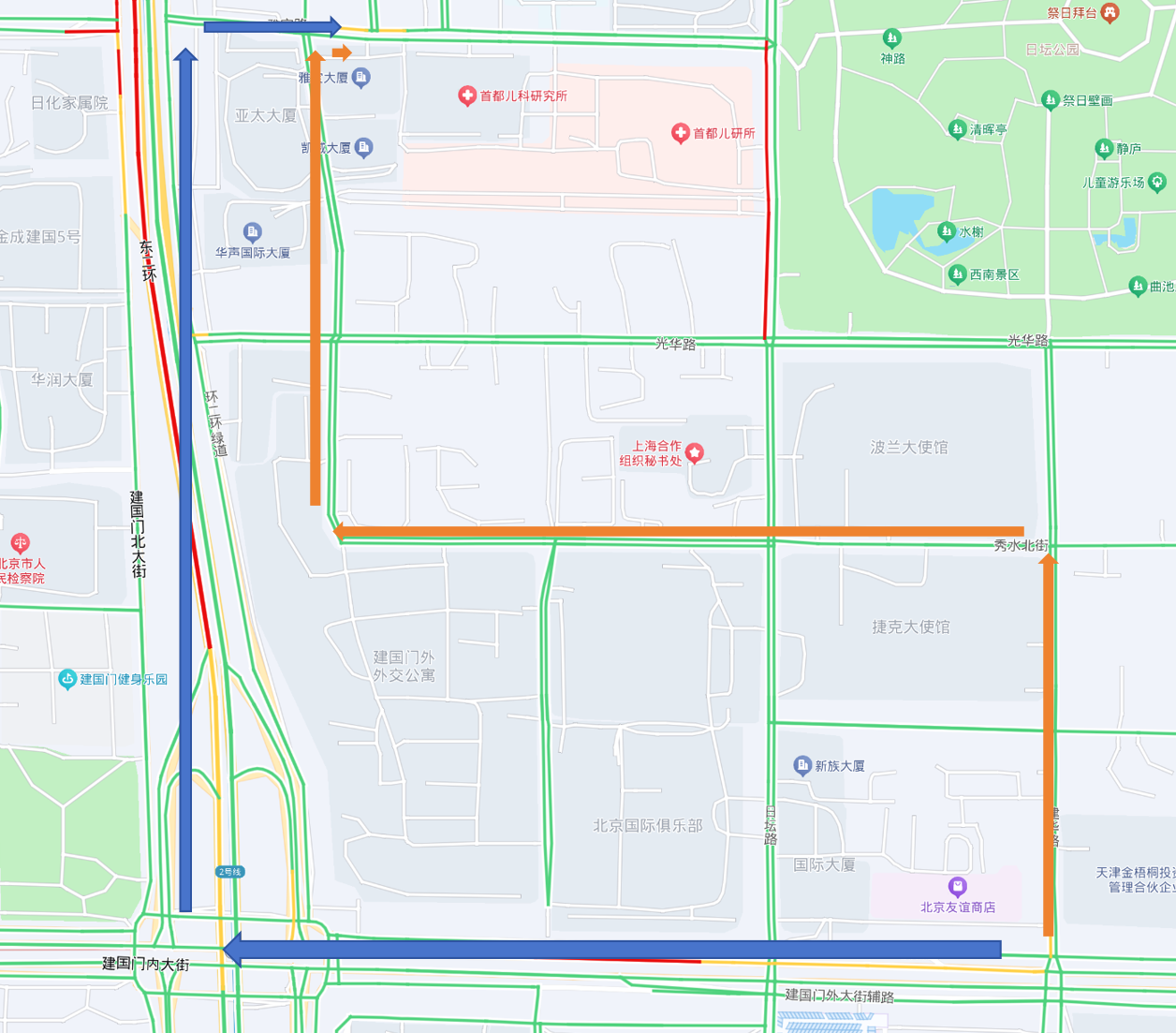
这是北京某区域某时刻的路况信息
传统编程是这样的:你给外卖员画了一张地图,上面标好了每一条路,告诉他“从商家出门左拐,走到第二个红绿灯右转,直走三百米看到小区大门进去”。(蓝色路线)
深度学习就不一样了。你没给他画路线,但你给了他过去半年这个区域所有外卖订单的记录:每一单是从哪个店送到哪个小区、走了哪条路、花了多长时间。他拿着这些数据自己研究,慢慢就明白了:“哦,中午十二点这条路特别堵不能走”。以后你给他一个新订单,他没有现成的路线,但他能根据自己从数据里学到的东西,当场判断出一条最优路线。(橙色路线)
基础代码
我们首先使用PyTorch做一个简单的事情
result = a + b
这个看起来很简单,代码写起来也很简单,如果你刚才在上一个章节中阅读了代码,那么你很快就能发现你已经使用过了
import torch
x = torch.tensor(1.0)
y = torch.tensor(2.0)
print(x)
print(y)
print("=====")
result = x + y
print(result)
结果很明显
tensor(1.)
tensor(2.)
=====
tensor(3.)
经过上面的计算,可以将两个张量相加,得到结果。
等等,什么是张量?
2.张量
张量(Tensor)是深度学习中的基础数据结构,你暂时不需要了解他代表什么,你最多只需要了解,他算是一个多维数组,并且Python和PyTorch都提供了相应的API,可以方便的进行张量的创建、运算、保存、加载等等。
如果你对线性代数还有些了解,那么二维张量就可以看作是一个矩阵。
# 创建一个二维张量(矩阵)
# [1.0, 2.0]
# [3.0, 4.0]
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
如果你对线性代数有更多的记忆,那么你肯定还记得向量,标量,矩阵乘法这种知识点。
而我们第一张使用的tensor(1.)其实就是一个标量,也就是一个数字。
# 标量
x = torch.tensor(1.0)
# 向量
y = torch.tensor([1.0, 2.0])
i = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
j = torch.tensor([[5.0, 6.0], [7.0, 8.0]])
# 矩阵乘法
print(i@j)
创建张量的方式有很多,可以直接指定值,也可以只指定形状,然后随机生成值。
你甚至可以根据一个张量的形状,来创建另一个张量。
## 大家可以自己运行一下,看看这些创建出来的张量都是什么样子
a = torch.tensor([1, 2, 3, 4, 5])
b = torch.zeros(3, 4)
c = torch.ones(2, 3)
d = torch.randn(2, 3)
e = torch.arange(0, 10, 2)
f = torch.linspace(0, 1, steps=5)
print(f"从列表: {a}")
print(f"全零 3x4:\n{b}")
print(f"全一 2x3:\n{c}")
print(f"正态随机:\n{d}")
print(f"arange: {e}")
print(f"linspace: {f}")
print(f"\n形状: {d.shape}, 类型: {d.dtype}, 设备: {d.device}, 维度数: {d.ndim}")
t = torch.randn(2, 3)
print(f"\nfloat32 -> int32: {t.to(torch.int32).dtype}")
print(f"float32 -> float64: {t.to(torch.float64).dtype}")
⏸️ 如果看到这里累了,可以直接看下一章,等有需求再回来看
张量的其他属性
在上面的例子中,我们可以看到张量的形状,类型,设备,维度数。
这些其实都很好理解
- 形状:张量的形状大小
- 类型:张量的数据类型
- 设备:张量存储的设备
- 维度数:张量的维数
需要说明的是设备:
- CPU:CPU设备,默认设备
- GPU:GPU设备
创建张量的时候,可以指定设备,但是默认是CPU设备。
x = torch.tensor([1, 2, 3], device='cpu')
# 如果运行接下来的代码,没有GPU设备,那么会报错
y = torch.tensor([1, 2, 3], device='cuda:0')
print(x.device)
print(y.device)
以下是其他的属性,简单看看就好
tensor = torch.tensor(
data=[[1, 2, 3], [4, 5, 6]],
dtype=torch.float32,
device=torch.device('cuda:0'),
requires_grad=True
)
# 查看所有主要属性
print("data:", tensor) # 张量本身的值
print("shape:", tensor.shape) # 形状 (2, 3)
print("ndim:", tensor.ndim) # 维度数 2
print("dtype:", tensor.dtype) # torch.float32
print("device:", tensor.device) # cuda:0 或 cpu
print("requires_grad:", tensor.requires_grad) # 是否需要梯度(用于自动微分)True
print("is_cuda:", tensor.is_cuda) # 是否在GPU上
print("layout:", tensor.layout) # torch.strided(默认密集布局)
print("itemsize:", tensor.itemsize) # 每个元素字节数(float32为4)
print("nbytes:", tensor.nbytes) # 总字节数 = shape[0]*shape[1]*itemsize = 2 * 3 * 4=24
print("numel:", tensor.numel()) # 元素总数 6
print("stride:", tensor.stride()) # 步长,访问下一个行/列时需要跳过的元素数 (3, 1)
print("grad:", tensor.grad) # 梯度(目前为None,因为还没反向传播)
print("grad_fn:", tensor.grad_fn) # 梯度函数(叶子节点为None)
print("T:", tensor.T) # 转置后的张量(视图)
print("H:", tensor.H) # Hermitian转置(共轭转置,复数才有效)
print("mH:", tensor.mH) # 同上
print("real:", tensor.real) # 实部(实数张量就是自身)
print("imag:", tensor.imag) # 虚部(实数张量为0)
张量的计算
张量的计算很方便,我们只需要使用Python自带的运算符即可
x = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
y = torch.tensor([[5.0, 6.0], [7.0, 8.0]])
print(f"x:\n{x}\ny:\n{y}")
print(f"x + y:\n{x + y}")
print(f"x + y:\n{x.sum(y)}")
print(f"x * y (逐元素!):\n{x * y}")
print(f"x @ y (矩阵乘法!):\n{x @ y}")
print(f"求和: {x.sum()}, 沿行求和: {x.sum(dim=0)}, 沿列求和: {x.sum(dim=1)}")
print(f"均值: {x.mean()}, 最大值: {x.max()}, 最大值索引: {x.argmax()}")
print(f"\n广播: x + 10 =\n{x + 10}")
print(f"广播: x + [10, 100] =\n{x + torch.tensor([10.0, 100.0])}")
❗注意:张量进行运算时要保证设备同在CPU或者GPU上,否则会报错
在上述的运算代码中,我们可以看到加法是有多种计算方式的,其实还有更多
我们以加法为例,如果想了解其他计算方式,可以自行查询
a = torch.tensor([[1,2,3]])
b = torch.tensor([[10],[20]])
# 以加法为例
c = a + b
c = torch.add(a, b)
c = a.add(b)
a.add_(b)
# 广播
a = torch.tensor([[1,2,3]]) # shape (1,3)
b = torch.tensor([[10],[20]]) # shape (2,1)
c = a + b # 结果 shape (2,3)
上述代码中有两点需要说明:
-
原地加法:
这些加法操作中有一个特殊的方法:add_。这个加法与其他的写法不同处在于:add_方法会改变原张量的值,而其他方法不会。比如刚才的a.add_(b)运算,他会直接将计算的结果赋给a,a的值会改变。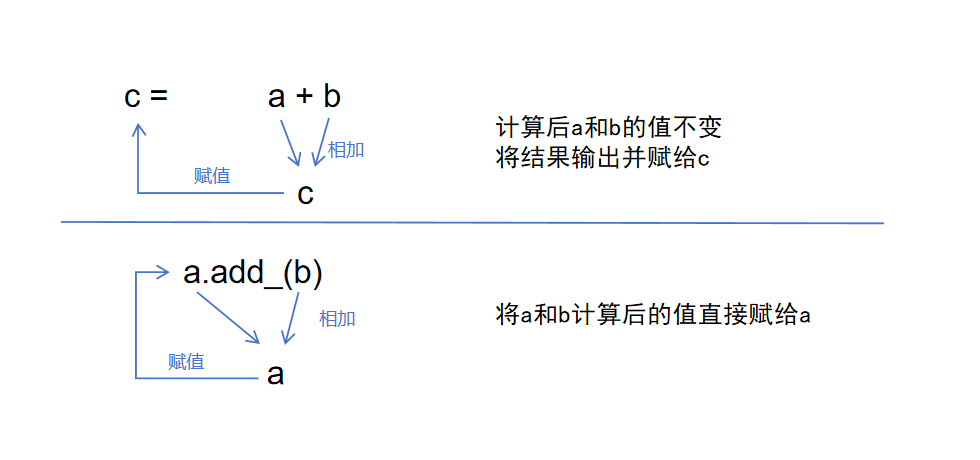
-
广播:
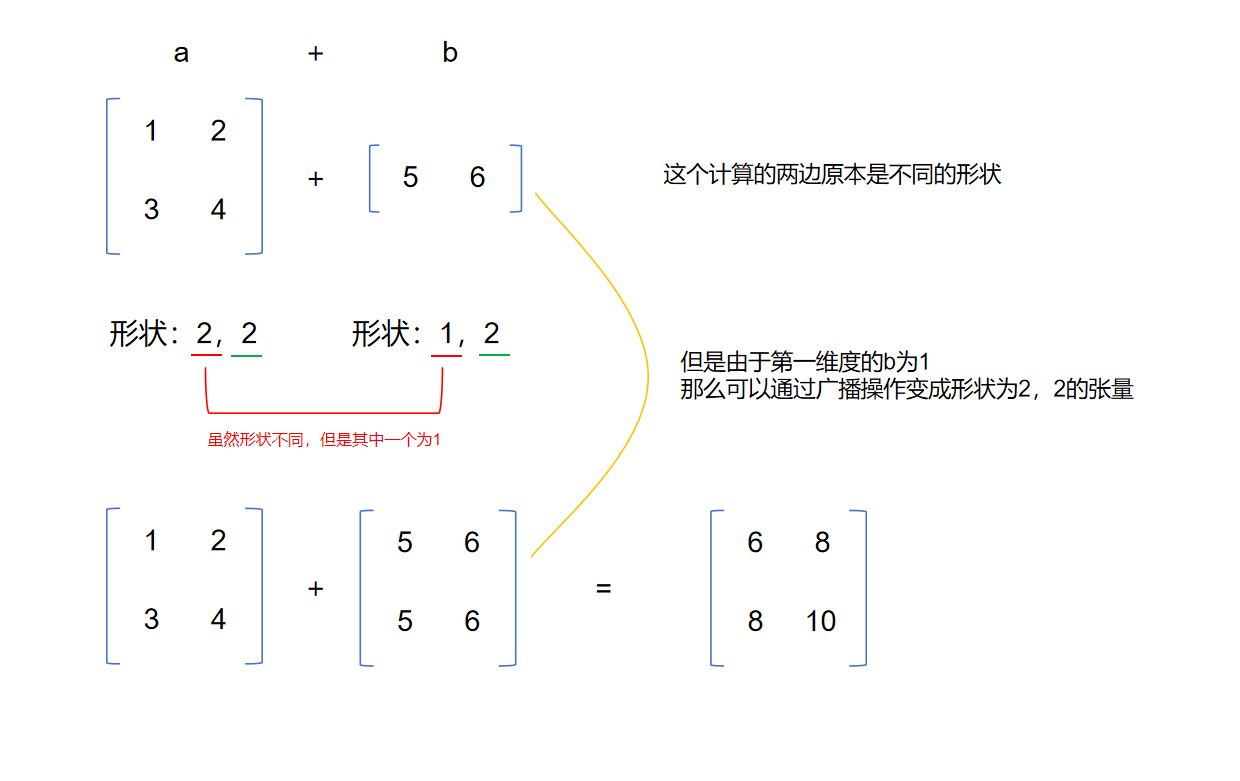
当两个张量形状不同但在运算时满足广播条件,那么允许这两个向量进行运算。刚才举的例子中,a的形状是(1,3),b的形状是(2,1),虽然两个张量的形状不同,但是a的第一个维度是1,b的维度是2,那么a的维度1会自动扩展为(2,1),两个张量形状相同,那么两个张量就会进行运算。
3. 训练一个模型从开始到结束的流程
在谈论模型训练之前,我们先举一个例子:还是外卖员送货:
(接下来是吴恩达的PyTorch课程中的例子)
假设你是一个资深外卖员,本月送货已经迟到了4次,如果再迟到一次,那么这个外卖员就要被裁员了。
现在有一个新的单子派发过来:客户要求30分钟内送往7公里(原例为英里)的位置。那么如果你接了这个单子,会迟到吗?
(AI生成的图片)
既然你已经是个资深的外卖员了,那你肯定也经历过不同的外卖配送单,假设你拥有一些历史交付数据:
| 距离(公里) | 时间(分钟) |
|---|---|
| 2.0 | 11.9 |
| 3.0 | 15.3 |
| 4.0 | 18.8 |
| 5.0 | 22.2 |
| 6.0 | 25.6 |
具体在坐标轴上,是这样展示出来的:
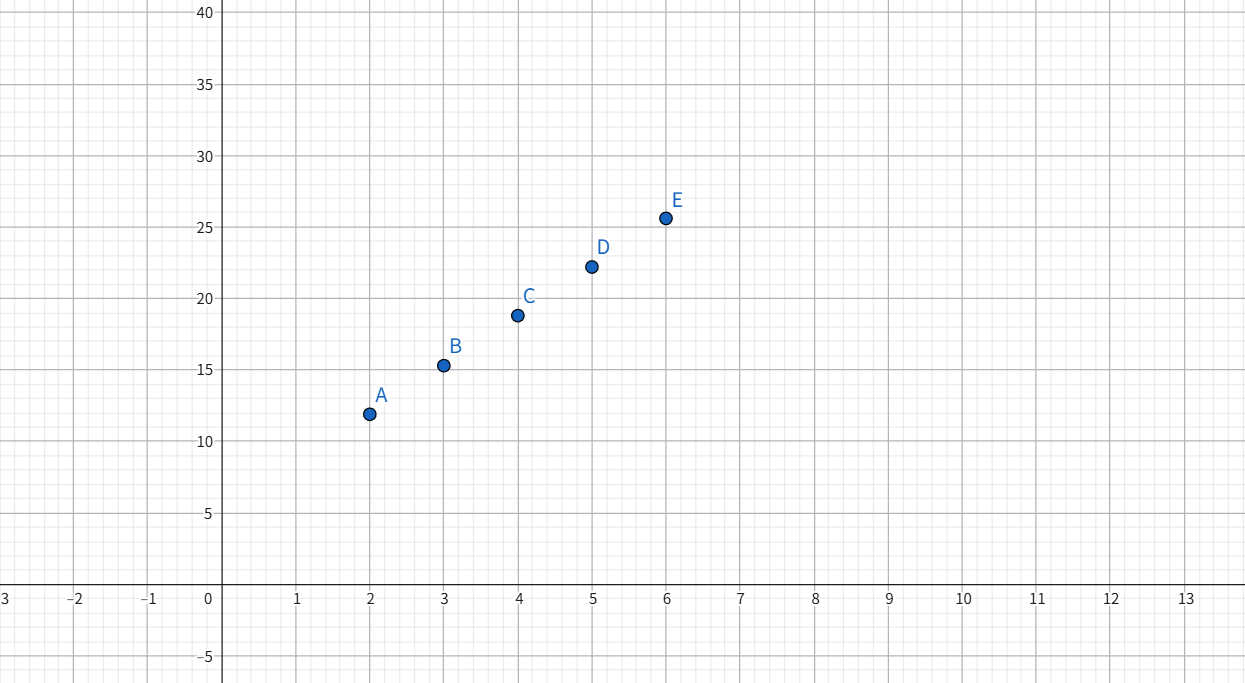
很明显,根据公里的变化,时间也程线性变化。那你现在想象一下,7公里大致可以多长时间到达?
我们可以很简单的推测出来,7公里大致耗时在28-30分钟之间
我们也可以预测这几个点的最佳拟合直线,并查看他在x=7上y的位置
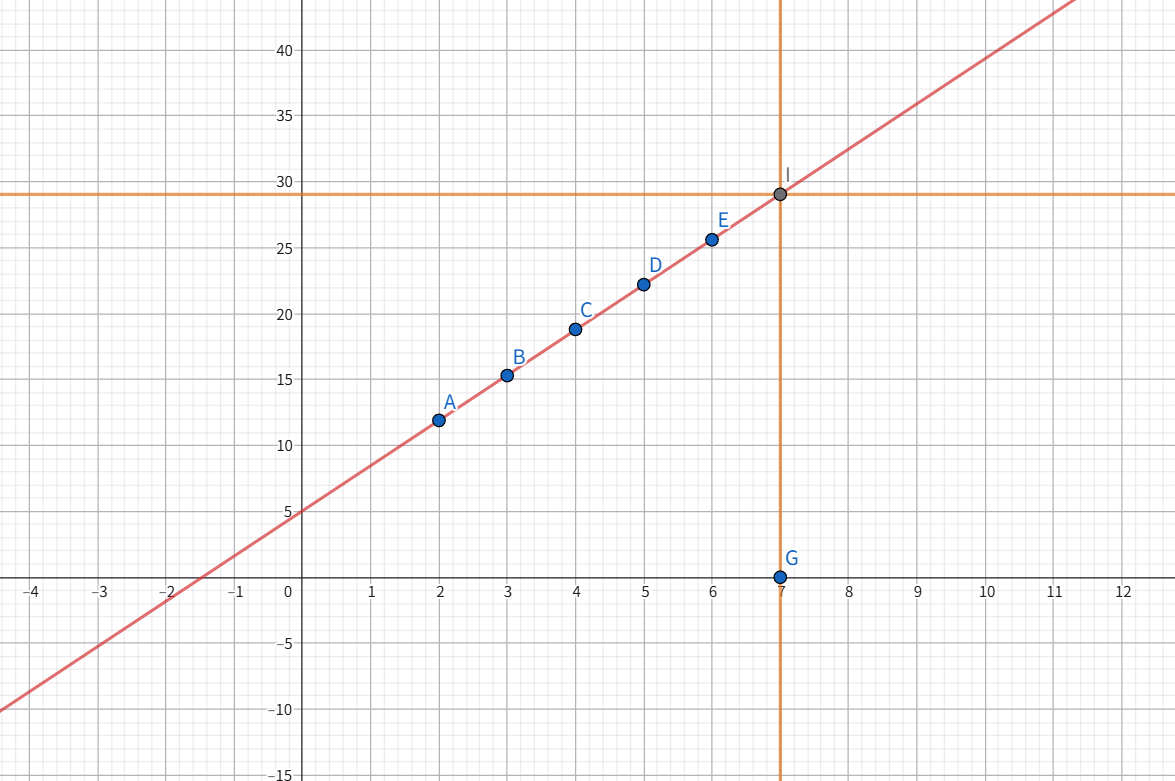
其中红色为预测直线,i点为x=7在预测直线上的位置,他很明显没有超过30分钟。
⚠️说明:其实这个预测直线是有很大的问题的,因为x坐标代表的是距离,y代表时间,但是在这里明显x和y都走向了负数,而且当公里数为0时也需要花费5分钟,这样也是不合理的。总的来说这个直线很不值得推敲。
现在我们通过简单的猜测以及图示,已经能够预测出我们可以在规定时间内完成这个配送单。
我们这是个PyTorch教程,并不是智力开发教程。接下来,我们开始训练一个模型,来预测这个结果。
了解神经网络
什么?这么快?已经开始学习神经网络了?
其实神经网络并没有我们想的那么复杂,我们简单的通过一个图来看一下一个神经网络的架构:
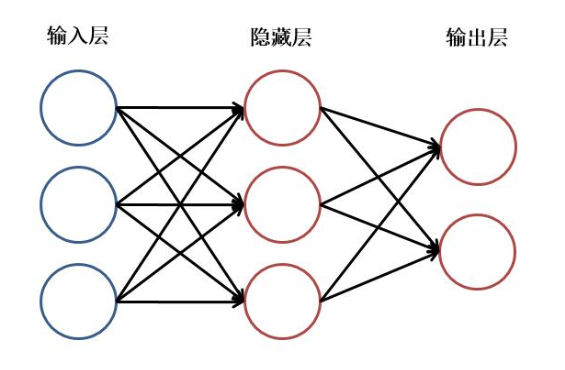
大家可以看到,这是一个简单的神经网络,其中的圆形我们称之为神经元。
神经元分为线性和非线性两种。我们暂时忽略非线性神经元,只考虑线性神经元。
线性神经元
线性神经元,就是我们最基础的计算单元,他内部仅仅是一个具有两组参数的函数:权重w和偏置b
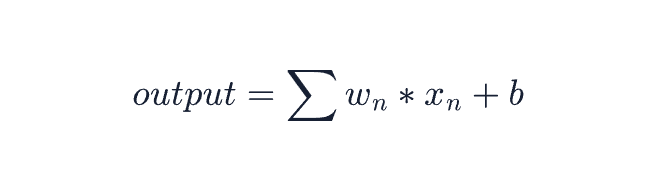
再简单一点说,如果我们只有一个输入x,那么这个神经元的输出为:output = wx + b
那么我使用训练数据时,即使用正确的x和output这两个值,并提供给模型,深度学习的训练过程,就是通过不断调整权重w和偏置b,使得预测值和真实值之间的误差最小化。在这个阶段,实际上就是机器学习在“学习”。
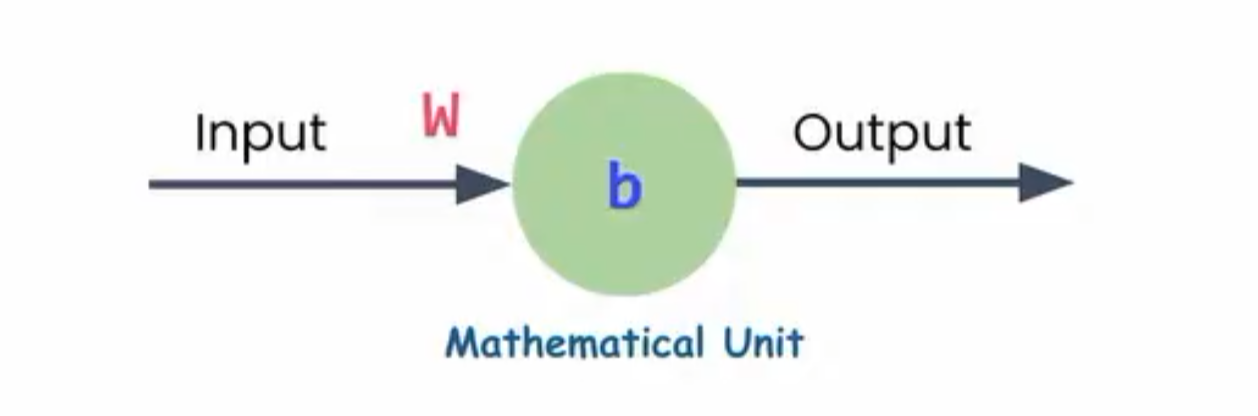
哇 这样很直观吧
也就是说,权重w和偏置b就是模型的参数
那问题就从如何预测出来这个output值,变成了如何判断哪个w和b是最佳的(哪条线是最佳的)
我们先瞎猜一个:假设权重为1,偏置为10,那么这个神经元的输出为:output = x + 10
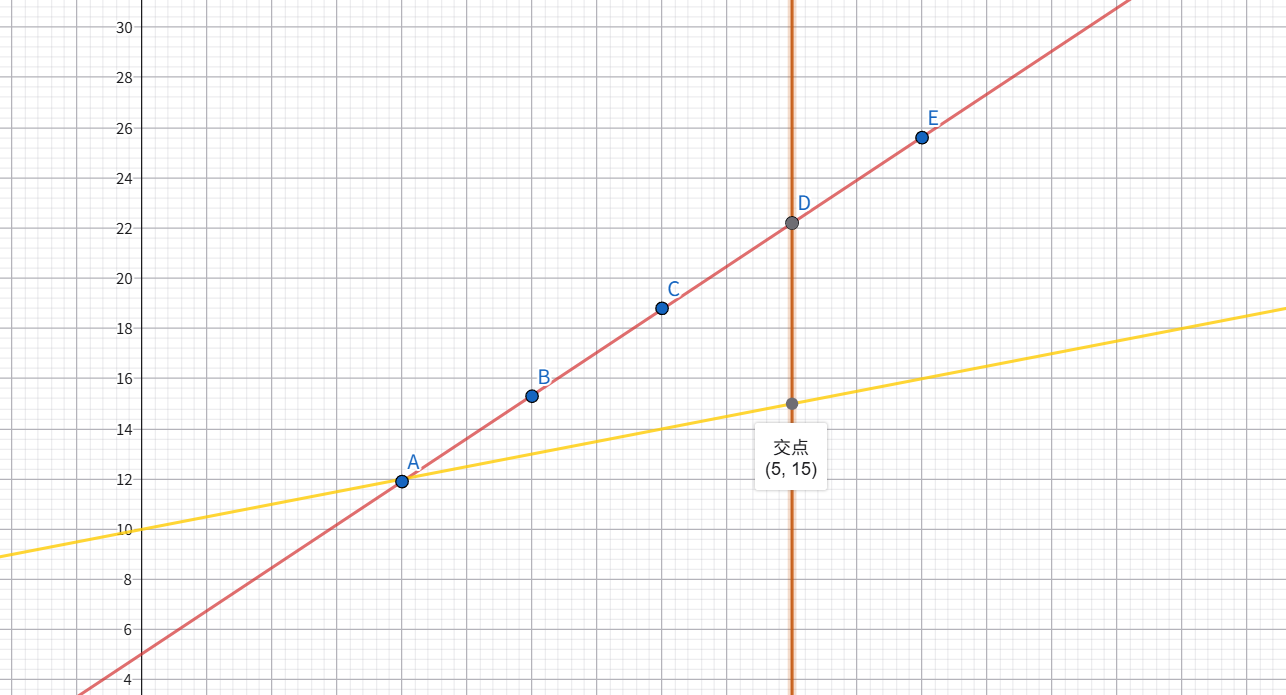
黄色则是第一次猜出的直线,可以发现当距离为5的时候,这个直线的输出为15,这个输出值与真实值之间的误差为7.2,所以我们可以认为这个直线并不是最佳的,或者说还有优化的空间。
我们再猜一个:假设权重为3.4,偏置为5,那么这个神经元的输出为:output = 3.4x + 5
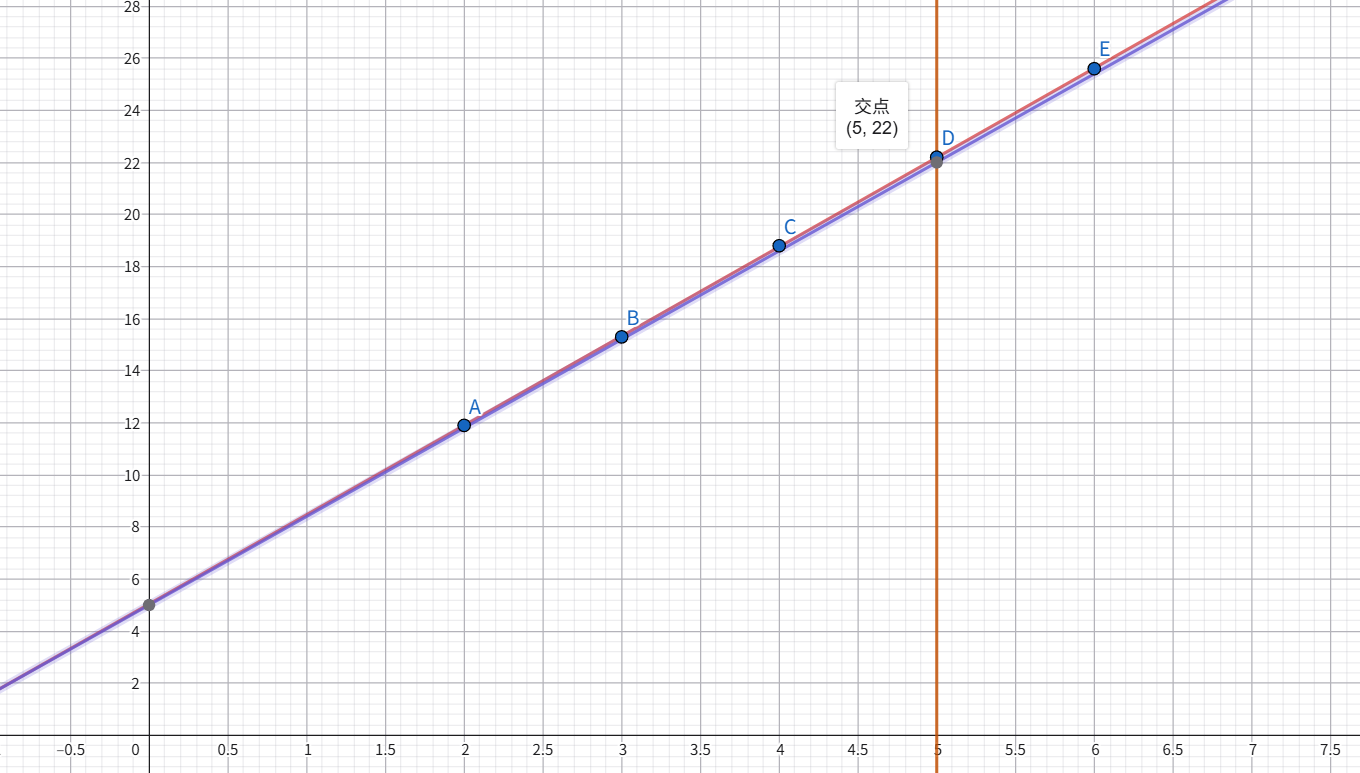
天哪,那是接近的
这两条线已经接近重合了,当距离为5的时候,这个直线的输出为22,这个输出值与真实值之间的误差仅为0.2,所以我们可以认为这个直线快要达到最佳了。
那么我们总结一下, 刚才我们为了让神经元学习,调整了权重w和偏置b,使得预测值和真实值之间的误差最小化。
然而我们是通过直觉来调整的,PyTorch则不一样。
神经元则是以随机的权重和偏置开始,每次参数调整结束后将预测值与结果值进行比较,与结果越远,整体的误差也就越大,随后通过算法(微积分)来不断调整权重和偏置的方向。
这就好像是,我第一次预测结束后获得了一个误差值,那么我条整理一下参数,误差值是增大了还是减小了?发现误差值减小了,我们就确定了调整的方向,从而向正确的方向调整更细微的参数,最终可能会找到最接近最佳的参数(误差值最小的参数)。
训练一个神经网络
即使一个神经网络中仅存在一个线性神经元,也叫一个神经网络。
好,我们来开始训练一个神经网络。
等等,在这之前,我们需要了解,训练神经网络都需要哪些步骤
训练步骤
- 步骤1:数据获取
训练神经网络,需要一个数据集,数据集一般分为训练集和测试集,训练集用于训练模型,测试集用于评估模型。
假设说我们需要训练一个模型来认识手写的字,那么你就需要获取多组训练图片以及它的对应的字。

在上面的例子中,图片就是我们的训练数据,而他对应的数字就是我们的训练标签。这一个照片和一个标签,我们就称为一组数据,多组数据合并起来就是一个数据集。
训练集和测试集的划分,一般使用80%和20%的比例。
但是需要说明的是,有些数据属于脏数据,如果使用脏数据进行训练,那么训练的模型就会有较大的误判率。假设说刚才例子中的外卖员,获取到一个数据组为:距离为5公里,时间为-10分钟。拿着很明显是一个脏数据。类似于这种脏数据需要在这个阶段筛选掉。
- 步骤2:数据预处理
数据预处理,就是将数据进行清洗、转换、归一化等操作,使得数据符合神经网络的要求。
假设说我们获取到的数据为: 从a地址到b地址,需要20分钟。 很明显这不是脏数据,但是他没有达到训练要求,因为我们希望训练的模型输入的数据为距离,所以需要将“从a地址到b地址”这样的数据进行转换。
- 步骤3:模型定义
模型定义,就是定义一个神经网络,这个神经网络由多个神经元组成。
在我们现在这个例子中,我们只需要设计单个线性神经元即可
- 步骤4:模型训练
模型训练,就是将训练集的数据进行训练,并让模型参数(权重w和偏置b)得到最接近训练集的参数。
- 步骤5:模型评估和调试
模型评估和调试,就是将测试集的数据进行评估,并查看模型的预测结果与真实结果之间的误差。
- 步骤6:模型部署
多次训练,多次评估,最终得到一个最接近训练集的模型。此时我们就可以将这个模型部署到实际使用中。
代码实现
好的!我们终于可以开始写代码了!
import torch
import torch.nn as nn
import torch.optim as optim
# ====== 数据:距离(公里) → 时间(分钟) ======
x_data = torch.tensor([[2.0], [3.0], [4.0], [5.0], [6.0]]) # 距离
y_data = torch.tensor([[11.9], [15.3], [18.8], [22.2], [25.6]]) # 时间
# ====== 模型:单个线性神经元 y = wx + b ======
model = nn.Sequential(nn.Linear(1, 1)) # 1个输入 → 1个输出(无激活函数 → 线性)
loss_fn = nn.MSELoss() # 均方误差损失
optimizer = optim.SGD(model.parameters(), lr=0.05) # SGD 优化器
print("初始参数:")
print(f" w = {model[0].weight.item():.4f}, b = {model[0].bias.item():.4f}\n")
# ====== 训练 500 次 ======
for epoch in range(500):
y_pred = model(x_data) # 前向传播
loss = loss_fn(y_pred, y_data) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
if (epoch + 1) % 50 == 0:
print(f"Epoch {epoch+1:3d} loss = {loss.item():.6f}")
# ====== 结果 ======
w, b = model[0].weight.item(), model[0].bias.item()
print(f"\n训练完成 → w = {w:.4f}, b = {b:.4f}")
print(f"公式:时间 = {w:.4f} × 距离 + {b:.4f}")
# 预测一个值试试
test_dist = torch.tensor([[7.0]])
pred = model(test_dist)
print(f"\n预测:距离 7.0 公里 → 时间 {pred.item():.2f} 分钟")
好的,我们目前可以复制上面的代码来运行,但是下面我会一步一步拆开来解释这些操作。
我们来讲解一下:首先我们要了解我们引用了哪些东西
- torch: 提供pytorch的核心功能
- nn: 提供神经网络相关的功能
- optim: 提供优化器的功能(训练神经网络的工具)
数据获取/数据预处理
首先,我们观察上一个章的操作步骤,会发现我们已经省略了 步骤1:数据获取 和 步骤2:数据预处理 。这是因为数据本身已经达到了可以训练的程度,后续可以学习数据的相关操作,但是在这里,我们可以暂时忽略。
那么张量,就成为了我们存储数据集的容器
# ====== 数据:距离(公里) → 时间(分钟) ======
# 需要说明的是,如果张量的数值为小数,则默认dtype为torch.float32
x_data = torch.tensor([[2.0], [3.0], [4.0], [5.0], [6.0]]) # 距离
y_data = torch.tensor([[11.9], [15.3], [18.8], [22.2], [25.6]]) # 时间
在这个例子中,x始终为一个,如果出现多个,比如天气情况,时间段等,可能会出现多个参数。
x_data = torch.tensor([[2.0, 1], [3.0, 0], [4.0, 0], [5.0, 1], [6.0, 1]]) # 距离,是否白天
但是在这个例子中我们暂时用不到
模型定义
接下来,我们开始定义这个模型,我们需要创建神经网络
# ====== 模型:单个线性神经元 y = wx + b ======
model = nn.Sequential(nn.Linear(1, 1)) # 1个输入 → 1个输出(无激活函数 → 线性)
loss_fn = nn.MSELoss() # 均方误差损失
optimizer = torch.optim.SGD(model.parameters(), lr=0.05) # SGD 优化器
其中model就是我们定义的神经网络,内部包裹着一个神经元。
下面两个分别为损失函数和优化器:
损失函数具体来说就是计算每次预测和实际的标签之间的损失值的,损失值越大代表预测的参数越不准确。
优化器简单来说就是提供给下一次模型预测参数的算法。
这两部分我们后期会单独讲
模型训练
开始训练!
# ====== 训练 500 次 ======
for epoch in range(500):
optimizer.zero_grad() # 梯度清零
y_pred = model(x_data) # 前向传播
loss = loss_fn(y_pred, y_data) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
if (epoch + 1) % 50 == 0:
print(f"Epoch {epoch+1:3d} loss = {loss.item():.6f}")
好的 这里面就比较复杂了,这里一共循环500次,很明显每次循环共经历了五步,但是实际这五步在上面讲解神经元的时候都已经走过了。我们这次再走一遍:
-
梯度清零
这一步实际上是清理掉上次所有计算的值,防止上次的数据会影响到本次的计算。 -
前向传播
这一步其实就是根据已经存在的权重和偏置,传入x_data,来输出预测的output(y_pred) -
计算损失
可以看到这个计算损失就是使用了损失函数。通过损失函数可以给当前模型"打分",分数越高则代表损失越大 -
反向传播
这一步就是根据上一步打出的"分数",思考如何调整权重和偏差以减少分数 -
更新参数
上一步偏向于思考,而这一步更偏向于实践。将调整的策略应用于参数上以便于下一次训练。
模型评估和调试
经过500次循环的五步走,后我们得到了最终的模型结果,现在我们来评估一下
# ====== 结果 ======
w, b = model[0].weight.item(), model[0].bias.item()
print(f"\n训练完成 → w = {w:.4f}, b = {b:.4f}")
print(f"公式:时间 = {w:.4f} × 距离 + {b:.4f}")
# 预测一个值试试
test_dist = torch.tensor([[7.0]])
pred = model(test_dist)
print(f"\n预测:距离 7.0 公里 → 时间 {pred.item():.2f} 分钟")
这个时候我们就已经可以打印出来权重w和偏置b了,并且输入7.0,我们可以预测出所需要的时间
那么到此,我们就已经训练出人生中的第一个神经网络了,接下来是我自己训练后的结果输出
初始参数:
w = 0.2463, b = -0.0089
Epoch 50 loss = 0.672430
Epoch 100 loss = 0.231203
Epoch 150 loss = 0.080161
Epoch 200 loss = 0.028050
Epoch 250 loss = 0.010071
Epoch 300 loss = 0.003867
Epoch 350 loss = 0.001727
Epoch 400 loss = 0.000989
Epoch 450 loss = 0.000734
Epoch 500 loss = 0.000646
训练完成 → w = 3.4345, b = 5.0198
公式:时间 = 3.4345 × 距离 + 5.0198
预测:距离 7.0 公里 → 时间 29.06 分钟